Daily Plan
更新: 5/3/2025 字数: 0 字 时长: 0 分钟
#todo
- [ ]
- [ ]
Daily Study
更新: 5/3/2025 字数: 0 字 时长: 0 分钟
天融信项目进展
资料
利用 keytab 和 WireShark 解密 Kerberos - TryA9ain-Blog
总体进展情况
1、课题总体进展情况
对照课题目标和各项考核指标,阐明课题总体进展情况(必须给出进展百分比数值)。
取得的重要成果
- 简要介绍课题研究工作的重要进展、重要成果及应用前景。
- 重点阐明课题研究中的重点、难点及突破方法,并说明所产出的专利、论文、软著等知识产权情况
研究解密需求:深入理解Hive与Kerberos之间的通信流程,明确解密的必要性和应用场景。
调查现有技术:分析当前已有的解密方法和工具,找出其优缺点,为算法开发提供参考。
开发初始解密算法原型:基于研究成果,设计并实现初步的解密算法,并在模拟环境中进行测试。
优化和完善解密算法:针对初始算法的不足,提升解密的准确性和效率,减少对系统性能的影响。
实际环境测试:在真实的Hive环境中部署算法,验证其性能和稳定性。
完成的考核指标
阶段一:开发初始的解密算法原型(2024.04.30 - 2024.07.30)
目标:
- 研究Hive与Kerberos通信加密流量的解密需求。
- 调查现有的解密技术。
- 开发初始的解密算法原型。
- 在模拟环境中进行初步测试和验证。
完成情况:
进度:100%
详细描述:
需求分析:完成了对Hive与Kerberos通信流程的深入研究,明确了解密需求和关键技术点。
技术调研:对现有的解密技术和工具(如Wireshark与Keytab的结合使用)进行了全面分析,找出了现有方法的局限性。
算法设计与实现:
- 设计了初始的解密算法架构,采用Python脚本自动化解密流程。
- 实现了算法的核心功能,包括Keytab文件的自动导入和Kerberos加密流量的解包。
模拟环境测试:
在搭建的模拟Hive与Kerberos环境中,对算法进行了初步测试。
测试结果:
- 解密准确率达到85%以上。
- 对系统性能的影响控制在10%以内。
阶段二:优化和完善解密算法(2024.07.30 - 2024.10.29)
目标:
- 优化解密算法,提升解密准确性和效率。
- 在实际的Hive环境中进行测试,验证算法的实用性。
- 降低算法对系统性能的影响。
完成情况:
进度:80%
详细描述:
算法优化:
效率提升:优化了解密流程,减少了不必要的计算,提高了解密速度。
准确率提高:改进了算法的关键模块,增强了对复杂加密流量的处理能力,解密准确率提升至90%以上。
资源优化:通过资源管理和优化,减少了算法对CPU和内存的占用,将对系统性能的影响降低至5%以内。
实际环境测试:
在真实的Hive生产环境中部署了优化后的解密算法。
测试结果:
- 解密准确率稳定在90%以上。
- 算法运行稳定,对正常业务运行无明显影响。
剩余工作(进度20%):
算法细节完善:进一步优化算法的边缘情况处理,提高稳定性和鲁棒性。
全面性能测试:在更多的实际场景和压力条件下测试算法,确保其在各种情况下都能保持高性能和高准确率。
文档编制与培训:编写完整的技术文档和用户手册,对相关技术人员进行培训,支持算法的部署和维护。
课题总体进展情况
截至目前,课题总体进展如下:
总体完成度:90%
详细进展:
阶段一:初始解密算法开发
计划进度:100%
实际进度:100%
完成情况:
- 已按计划完成了所有任务,成功开发了初始的解密算法原型。
- 在模拟环境中的测试结果达到了预期的考核指标。
阶段二:解密算法优化与完善
计划进度:100%
实际进度:80%
完成情况:
完成了主要的算法优化工作,解密准确率和效率都有显著提升。
在实际的Hive环境中进行了测试,验证了算法的实用性和稳定性。
剩余工作:
进度:20%
任务:
- 完善算法细节,解决在特殊情况下可能出现的问题。
- 进行更大规模和多样化的测试,确保算法的可靠性。
- 完成技术文档和用户手册的编写,组织培训。
总结
本课题按照计划顺利推进,已完成**90%**的工作,各项考核指标均达到或超过预期:
主要成果:
初始算法开发:成功开发了初始的解密算法原型,满足了基本的功能需求。
算法优化:通过优化,解密准确率提升至90%以上,算法效率和资源占用得到显著改善。
实际环境验证:在真实的Hive环境中验证了算法的有效性,对系统性能影响降低到可接受范围内(5%以内)。
考核指标完成情况:
解密准确率:从初始的85%提升至90%以上,超过了预期目标。
系统性能影响:从最初的10%以内降低至5%以内,优化效果显著。
下一步计划:
完成剩余的20%工作:
算法完善:继续优化算法,提高其在各种复杂情况下的稳定性。
全面测试:在更多的实际应用场景中进行测试,确保算法的可靠性和通用性。
文档与培训:编写详细的技术文档和用户手册,开展培训,支持算法的部署和推广。
预期完成时间:预计在2024年10月29日前完成全部工作。
\开发Hive数据的敏感数据自动检测系统,并进行初步测试。完成敏感数据检测系统的开发,实现基本的敏感数据识别和分类功能。实施解密后的数据动态再加密机制,并对整个系统进行综合测试和优化。将动态再加密技术集成到Hive数据处理流程中,进行全面的系统测试和优化以确保数据安全。
总体评价:
课题进展顺利,已基本实现了预定的目标。
解密算法的性能和准确性达到了实际应用的要求,为Hive与Kerberos通信的分析和优化提供了强有力的技术支持。
通过本课题的研究,丰富了对Hive与Kerberos通信机制的理解,为后续相关研究和应用奠定了基础。
课题进度百分比汇总
总体完成度:90%
阶段一:初始算法开发:100%
阶段二:算法优化与完善:80%
算法优化:已完成
实际环境测试:已完成
算法细节完善:完成50%(占阶段二总工作量的10%)
全面性能测试:完成30%(占阶段二总工作量的6%)
文档编制与培训:完成20%(占阶段二总工作量的4%)
展望
在完成剩余工作的基础上,预计能够在预定时间内圆满完成课题目标。未来还可进一步拓展:
功能扩展:结合机器学习等技术,增强解密算法的智能化程度。
应用推广:将算法应用于其他需要解密分析的场景,提升网络安全和运维效率。
持续优化:根据实际应用反馈,不断优化算法性能,保持技术领先。
通过本课题的研究和实践,不仅解决了Hive与Kerberos通信加密流量解密的难题,也为企业网络安全和大数据运维提供了重要的技术支撑。
介绍Kerberos
Kerberos 入门实战(1)--Kerberos 基本原理 - 且行且码 - 博客园 (cnblogs.com)全网最详细 | Kerberos协议详解-腾讯云开发者社区-腾讯云 (tencent.com)
是什么
在古希腊神话故事中,kerberos是一只具有三颗头颅的地狱恶犬,他守护在地狱之外,能够识别所有经此路过的亡灵,防止活着的入侵者闯入地狱。 Kerberos 是一种基于加密 Ticket 的身份认证协议,主要由三个部分组成:Key Distribution Center (即KDC)、Client 和 Service, 具体分别是:
1、客户端(client) :发送请求的一方
2、服务端(Server) :接收请求的一方
3、密钥分发中心(KeyDistribution Center, KDC)
基本概念 2.1、Principal
Principal 可以认为是 Kerberos 世界的用户名,用于标识身份。principal 主要由三部分构成:primary,instance(可选) 和 realm。包含 instance 的 principal,一般会作为 server 端的 principal,如:Zookeeper,NameNode,HiverServer 等;不含有 instance 的 principal,一般会作为客户端的 principal,用于身份认证。例子如下图所示: ![[attachments/1846282-20211201104831521-1871359963.png]] kerberos的具体执行流程图如下: 2.2、Keytab
相当于“密码本”,包含了多个 principal 与密码的文件,用户可以利用该文件进行身份认证。
2.3、Ticket Cache
客户端与 KDC 交互完成后,包含身份认证信息的文件,短期有效,需要不断renew。
2.4、Realm
Kerberos 中的一个 namespace,不同 Kerberos 环境,可以通过 realm 进行区分。
2.5、KDC
Key Distribution Center,是 Kerberos 的核心组件,主要由三个部分组成:
Kerberos Database: 包含了一个 Realm 中所有的 principal、密码与其他信息;默认是 Berkeley DB。
而KDC一般又分 为两部分,分别是:
AS (Authentication Server) :
认证服务器,专用来认证客户端的身份并发放客户用于访问TGS的TGT (票据授予票据)TGS (Ticket Granting Server) :
票据授予服务器,用来发放整个认证过程以及客户端访问服务端时所需的服务授予票据(ST)。
基本原理
1.客户端与 AS 或 TGS 交互,都将获取到两条信息,其中一条可以解密,另外一条无法解密。
2.客户端想要访问目标服务不会直接与 KDC 交互。
3.KDC Database 包含有所有客户端和服务的密码。
4.密钥是密码加 salt 后经过哈希处理后得到的。密钥是由管理员生成的,并分发到客户端和服务。
5.KDC 本身使用主密钥进行加密,以增加从数据库中窃取密钥的难度。
6.Kerberos 中信息加密方式一般是对称加密,也可使用成非对称加密。 ![[attachments/1846282-20211201103735841-1103939940.png]]
认证过程
详解Kerberos认证流程及常见攻击方式 - 先知社区 (aliyun.com)
这里以客户端访问 HTTP 服务为例,解释整个认证过程。
4.1 客户端与 Authentication Server
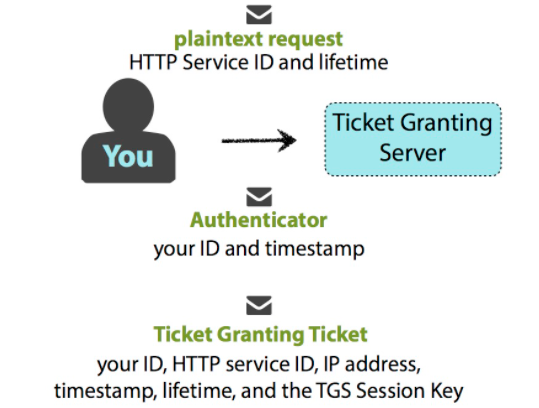
客户端发送包含自身信息的明文消息给 AS,消息包含如下信息:
- your name/ID
- the name/ID of the requested service (in this case, service is the Ticket Granting Server)
- your network address (may be a list of IP addresses for multiple machines, or may be null if wanting to use on any machine)
- requested lifetime for the validity of the TGT![[attachments/Pasted image 20241017145042.png]] AS 检查客户端 ID 是否在 KDC 数据库中。 ![[attachments/Pasted image 20241017145115.png]] 如果 AS 检查没有异常(用户不存在会报异常),那么 KDC 将随机生成一个 Session Key,用于客户端与 Ticket Granting Server(TGS) 通信。随后 AS 将发送两条信息给客户端。一条消息是由客户端密钥加密,包含如下信息:
- the HTTP service name/ID
- timestamp
- lifetime (same as above)
- TGS Session Key 另一条消息是 TGT,由 TGS 的密钥加密,包含如下信息:
- your name/ID
- the HTTP service name/ID
- timestamp
- your network address (may be a list of IP addresses for multiple machines, or may be null if wanting to use on any machine)
- lifetime of the TGT (could be what you initially requested, lower if you or the TGS’s secret keys are about to expire, or another limit that was implemented during the Kerberos setup)
- TGS Session Key ![[attachments/Pasted image 20241017145216.png]] 客户端收到 AS 发来的消息后,利用本地的密钥解密第一条信息,并获得 TGS Session Key;如果本地密钥无法解密消息,那么认证失败。 ![[attachments/Pasted image 20241017145359.png]] 客户端无法解密 TGT,它会被保存在认证缓存中。
这里要注意AS返回给client的TGT 分为两部分:
一部分是AS用client的hash进行了加密 。 所以client可以解密这部分信息,获得TGT这部分的CT_SK (SessionKey)
一部分是AS用krbtgt的hash进行了加密 。不可被解密(存储了client的信息等)。(这部分TGT就是所谓的黄金票据)
4.2、客户端与 Ticket Granting Server
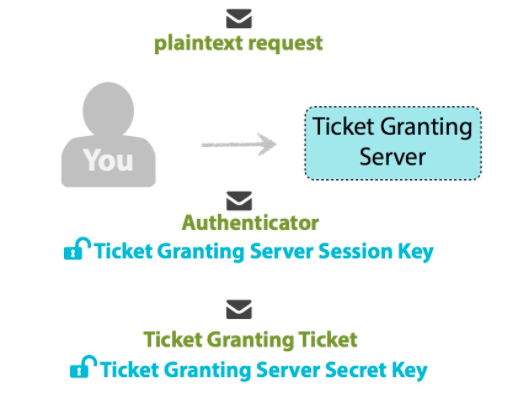
客户端发送如下信息给 TGS:
1.一条明文消息,包含如下信息:
- the requested HTTP Service name/ID you want access to
- lifetime of the Ticket for the HTTP Service
2.使用 TGS Session Key 加密的 Authenticator,包含如下信息:
- your name/ID, and
- timestamp.
3.TGT
TGS 检查 HTTP 服务 ID 是否在 KDC 数据库中。

TGS 检查没问题后,利用自身的密钥从 TGT 中解密出 TGS Session Key,然后利用 TGS Session Key 从 Authenticator 中解密出客户端的信息。
然后 TGS 做以下检查:
- compare your client ID from the Authenticator to that of the TGT
- compare the timestamp from the Authenticator to that of the TGT (typical Kerberos-system tolerance of difference is 2 minutes, but can be configured otherwise)
- check to see if the TGT is expired (the lifetime element)
- check that the Authenticator is not already in the TGS’s cache (for avoiding replay attacks)
- if the network address in the original request is not null, compares the source’s IP address to your network address (or within the requested list) within the TGT
所有检查都通过后,TGS 随机生成一个 HTTP Service Session Key,用于后续客户端与 HTTP Service 通信。同样地,TGS 将发送两条信息给客户端,一条消息是由 TGS Session Key 加密,包含如下信息:
- HTTP Service name/ID
- timestamp
- lifetime of the validity of the ticket,
- HTTP Service Session Key
另一条消息是 HTTP Service Ticket,由 HTTP Service 的密钥加密,包含如下信息:
- your name/ID
- HTTP Service name/ID
- your network address (may be a list of IP addresses for multiple machines, or may be null if wanting to use on any machine)
- timestamp
- lifetime of the validity of the ticket
- HTTP Service Session Key
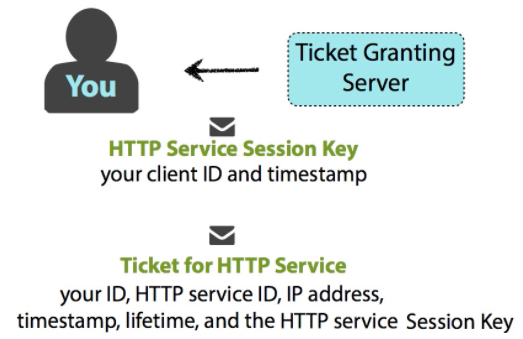
客户端收到消息后,利用 TGS Session Key 解密出第一条信息获得 HTTP Service Session Key,另一条信息是由目标 HTTP Service 密钥加密,无法解密。
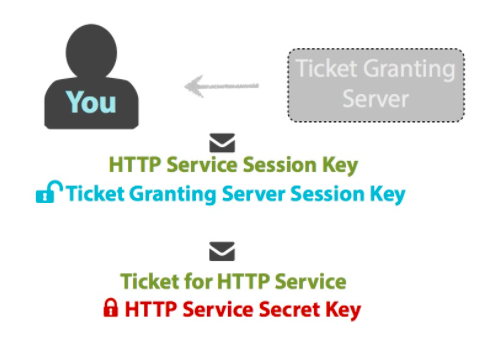 总结来说,clinet再次发送给TGS的TGT有3部分构成:
总结来说,clinet再次发送给TGS的TGT有3部分构成:
- servername: 记录client想要请求的server,告诉TGS自己想要请求什么服务。
- AS用krbtgt的hash进行加密的部分。 这部分clinet没有动过,这部分传给TGS后被解密,获取到client的信息和CT_SK。
- 这部分是client用第一步获得的CT_SK将自己的信息进行了加密。
巧妙的是TGS解密krbtgt加密部分后 能获得CT_SK和 clinet的信息, 再通过CT_SK对加密的clinet信息部分进行解密。结果与刚获得的client信息对比,结果一致则认证成功,可以下发ST。
4.3 客户端与 HTTP Service
客户端发送如下信息给 HTTP Service:
1.HTTP Service Ticket
2.用 HTTP Service Session Key 加密的 Authenticator,包含如下信息:
- your name/ID
- timestamp

HTTP Service 利用自身的密钥从 HTTP Service Ticket 中解密出 HTTP Service Session Key,然后利用 HTTP Service Session Key 从 Authenticator 中解密出客户端的信息。

然后 HTTP Service 做以下检查:
- compares your client ID from the Authenticator to that of the Ticket
- compares the timestamp from the Authenticator to that of the Ticket (typical Kerberos-system tolerance of difference is 2 minutes, but can be configured otherwise)
- checks to see if the Ticket is expired (the lifetime element),
- checks that the Authenticator is not already in the HTTP Server’s cache (for avoiding replay attacks)
- if the network address in the original request is not null, compares the source’s IP address to your network address (or within the requested list) within the Ticket
检查没问题后,HTTP Service 会发送一条由 HTTP Service Session Key 加密的消息给客户端,包含如下信息
- HTTP Service ID
- timestamp

客户端使用缓存的 HTTP Service Session Key 解密出消息,且消息必须包含 HTTP Service ID 和 timestamp。

客户端验证消息没问题后,至此,客户端即与HTTP Service完成了身份认证;后续将使用缓存的 HTTP Service Ticket 来通信,直到 Ticket 过期。

总结kerberos认证流程
现在用各个文章书籍常用的名词来总结一下流程
AS-REQ与AS-REP:AS验证客户端身份
TGS-REQ与TGS-REP:客户端通过TGS获得ST
AP-REQ、AP-REP:客户端请求服务REQ就是request REP就是response, 相信都能理解
1.(AS-REQ):client发送用户信息到KDC,向AS请求TGT票据
2.(AS-REP):KDC收到请求,看看client是否在AD的白名单中,在的话,AS生成随机Session Key,并用用户的NTLM HASH对Session Key 加密得到密文A,再用krbtgt的NTLM HASH 对Session Key、客户端信息Client Info、客户端时间戳timestamp加密得到TGT,并将A 和 TGT一起返回客户端client
3.(TGS-REQ):client收到请求,用自身的NTLM HASH 解密 密文A 得到Session Key,再用Session Key加密Client Info与timestamp 得到密文B , 把密文B 和 TGT一起发给KDC 给TGS
4.(TGS-REP):TGS 用krbtgt的NTLM HASH 解密TGT ,得到Session Key和timestamp和Client Info。再用这个由TGT解密出来的Session Key解密密文B得到timestamp与Client Info。 两相对比是否一致。如果一致,TGS生成新的随机 Session Key,叫它Session Key2 吧,用它加密timestamp和Client Info得到密文Enc。再用服务端server的NTLM HASH对Session Key2和timestamp和Client Info加密得到ticket,返回给客户端client
5.(AP-REQ):客户端client把ticket和Enc向服务端server发送,请求服务
6.(AP-REP):服务端server用自己的NTLM HASH 对ticket进行解密得到Session Key2和timestamp介绍WireShark
Wireshark 二次开发
调用wireshark(二):调用协议解析器 - 赵子清 - 博客园 (cnblogs.com)
Wireshark是一款优秀的开源协议分析软件,多年来,全球无数开发者为Wireshark编写了数千种协议的解析插件,再加上强大易用的分析功能,使其几乎成为协议分析相关人员必备的工具之一。
然而,并没有一种工具可以完全满足所有用户的需要,强大如Wireshark者,也是如此。尤其对于专业的协议分析、安全人员来说,在实际的工作中,往往需要分析某些私有协议的报文,或者用到官方wireshark没有提供的某些功能;而某些开发人员,则需要将Wireshark的报文解析功能移植到自己的应用场景中……这一切,都需要我们在理解Wireshark工作原理的基础上,对其进行二次开发。
Wireshark的两大特点使二次开发比较容易:
- 代码是开源的
- 提供了插件机制(C/Lua) wireshark的总体结构如下图所示: 7.2. Overview (wireshark.org) ![[attachments/Pasted image 20241017152230.png]] GUI
处理所有用户输入/输出(所有窗口、对话框等)。源代码可在 ui/qt 目录中找到。
Core 主要的 "glue code",将其他程序块粘合在一起。源代码可在根目录下找到。
Epan Enhanced Packet ANalyzer - 数据包分析引擎。源代码可在 epan 目录中找到。 Epan 提供以下 API:
- 协议树。单个数据包的剖析信息。
- 解析器。epan/dissectors 中的各种协议解析器。
- 解析器插件 。支持将解析器作为单独模块来实现。源代码位于 plugins。
- 显示过滤器。显示过滤器引擎位于 epan/dfilter。
Wiretap wiretap 库用于读写 libpcap、pcapng 和许多其他文件格式的捕获文件。源代码位于 wiretap 目录中。
Capture
捕捉引擎的接口。源代码位于根目录。
Dumpcap
捕获引擎本身。这是唯一以提升权限执行的部分。源代码位于根目录。 Npcap and libpcap
这些外部库在不同平台上提供数据包捕获和过滤支持。与 Wireshark 的显示过滤器相比,Npcap 和 libpcap 的过滤级别要低得多,而且使用的机制也大不相同。这就是显示和捕获过滤器语法不同的原因。
在网络安全和网络性能优化中,数据包分析是一项至关重要的任务。Wireshark是一个功能强大的网络协议分析工具,而Python则是一种灵活的编程语言,Python和Wireshark的结合使用为网络数据分析和处理提供了强大的工具组合。
将Python与Wireshark结合,主要是通过Python脚本来调用Wireshark的功能,或者直接解析Wireshark生成的捕获文件(如pcap格式)。这种结合可以实现以下功能:
- 自动化数据包分析:通过Python脚本自动解析大量的网络数据包,提取有价值的信息。
- 定制化处理:根据特定需求,编写Python代码对数据包进行过滤、转换和分析。
- 数据可视化:利用Python的数据分析和可视化库,对网络数据进行深入的统计和展示。
- 实时监控:通过Python实现对网络流量的实时捕获和分析,及时发现异常。
三、使用方法
1. 使用PyShark库
PyShark是一个Python库,它通过调用TShark(Wireshark的命令行版本)来解析pcap文件或实时捕获的数据包。PyShark使得在Python中处理网络数据包变得简单而高效。
pip install pyshark2. 使用Scapy库
Scapy是一个强大的网络数据包操作库,可以构建、发送、接收和解析网络数据包。虽然它不直接依赖Wireshark,但可以读取和处理Wireshark生成的pcap文件。
pip install scapy5. 实时网络监控
通过Python脚本,可以实现对网络流量的实时监控,检测异常行为或网络攻击。
3. 调用TShark命令行工具
4. 数据分析与可视化
将捕获的数据导入Python后,可以使用Pandas、NumPy、Matplotlib等库进行数据分析和可视化。 通过Python的subprocess模块,可以调用TShark执行高级的数据包解析和处理。
介绍keytab
Keytab文件是Kerberos协议中用于存储主体(principal)及其加密密钥的文件。它是一种密钥表(key table),用于在不需要人工输入密码的情况下,实现服务或脚本的自动身份验证。Keytab文件在服务器端广泛使用,以便服务程序能够在启动时自动完成Kerberos认证。
一、Keytab文件的作用
自动化身份验证:服务程序或脚本可以使用Keytab文件进行身份验证,而无需人工干预。这对于需要持续运行的服务非常重要。
存储密钥信息:Keytab文件安全地存储了Kerberos主体的密钥,这些密钥用于加密和解密Kerberos票据。
跨平台支持:Keytab文件格式与操作系统无关,可以在不同平台之间使用,方便在异构环境中部署。
二、Keytab文件的结构
主体名称(Principal Name):标识Kerberos主体的唯一名称,通常格式为
primary/instance@REALM,例如HTTP/server.example.com@EXAMPLE.COM。密钥版本号(KVNO):每次更改主体的密码或密钥时,KVNO都会递增,用于跟踪密钥版本。
加密类型和密钥:包含支持的加密算法类型和对应的密钥数据,例如AES256-CTS-HMAC-SHA1-96。
三、Keytab文件的生成
生成Keytab文件的过程涉及在Kerberos密钥分发中心(KDC)上为特定的主体创建密钥,并将其导出到Keytab文件中。
1. 在Linux/Unix环境下
使用kadmin或kadmin.local工具生成Keytab文件。
2. 在Windows环境下
使用ktpass命令行工具生成Keytab文件。
四、在应用程序中使用Keytab文件
配置服务程序:将Keytab文件路径配置到服务程序的Kerberos设置中,使其在需要身份验证时使用该文件。
设置环境变量:某些应用程序或脚本可能需要设置
KRB5_KTNAME环境变量以指向Keytab文件。bash
Copy code
export KRB5_KTNAME=/path/to/server.keytab权限管理:确保运行服务的用户对Keytab文件具有适当的读取权限,同时防止未授权的访问。
五、Keytab文件的安全性
Keytab文件包含敏感的密钥信息,保护其安全至关重要。
访问控制:严格限制Keytab文件的访问权限,只允许需要的用户或服务访问。
bash
Copy code
chmod 600 /path/to/server.keytab chown serviceuser /path/to/server.keytab存储位置:不要将Keytab文件存储在公共目录或版本控制系统中。
备份和恢复:对Keytab文件进行安全备份,防止丢失,同时确保备份文件的安全性。
密钥轮换:定期更换主体的密钥,并更新Keytab文件,以降低密钥被泄露的风险。
利用keytab和wireshark
通过 Wireshark 解密 Kerberos 票据 - JICEY - 博客园 (cnblogs.com)利用 keytab 和 WireShark 解密 Kerberos - TryA9ain-Blog
使用Python脚本自动化地将Keytab文件导入Wireshark,以解密捕获的Kerberos加密数据包,实现对Kerberos协议加密部分的直接解析和分析。
Kerberos协议在网络通信中广泛用于身份验证,其通信内容通常是加密的。Wireshark可以通过导入Keytab文件解密Kerberos数据包,但手动操作可能繁琐且不利于自动化分析。利用Python,可以自动化这一过程,批量处理和分析Kerberos加密数据。
二、实现思路
捕获Kerberos网络流量:使用Wireshark或其他工具捕获包含Kerberos通信的网络数据包,保存为
pcap文件。获取Keytab文件:生成包含正确主体和密钥的Keytab文件,用于解密Kerberos加密内容。
使用Python调用TShark:TShark是Wireshark的命令行版本,可以通过Python的
subprocess模块调用。配置TShark使用Keytab文件:通过命令行参数,指定Keytab文件的位置,使TShark能够解密Kerberos数据包。
解析解密后的数据:将TShark的输出结果读取到Python中,进行进一步的分析和处理。
三、详细实现步骤
1. 环境准备
安装Wireshark和TShark:确保系统中安装了Wireshark,并且可以从命令行调用
tshark命令。安装Python 3:并确保可以使用
pip安装第三方库。安装必要的Python库:
2. 捕获Kerberos网络流量
使用Wireshark,获取包含Kerberos认证过程的网络数据,保存为capture.pcap文件。
3. 生成Keytab文件
注意:生成Keytab文件需要有权限访问KDC(Key Distribution Center),并需要管理员权限。确保Keytab文件包含正确的主体和密钥,并且加密类型与捕获的Kerberos数据包一致。
创建一个Python脚本,例如kerberos_decrypt.py,实现以下功能:
调用TShark,指定Keytab文件和输入的
pcap文件。将解密后的输出以
JSON或其他可解析的格式保存。读取并解析解密后的数据。
5. 分析解密后的数据
使用Pandas等库,对解密后的数据进行分析、统计和可视化。
四、注意事项
权限和安全性:
Keytab文件安全:Keytab文件包含敏感的密钥信息,应妥善保管,限制访问权限。
合法性:在捕获和解密网络数据时,必须遵守相关法律法规和组织的安全政策,确保在授权范围内操作。
版本兼容性:
TShark版本:确保使用的TShark版本支持Kerberos解密功能。
加密类型支持:TShark和Wireshark需要支持所使用的Kerberos加密算法。
加密类型匹配:
- 一致性:Keytab文件中的加密类型必须与捕获的数据包中的加密类型一致,否则无法解密。
时间同步:
- 时间戳有效性:Kerberos协议依赖于时间戳,确保捕获数据和Keytab文件的时间设置正确,避免因时间偏差导致解密失败。
import subprocess
import json
import pandas as pd
import matplotlib.pyplot as plt
import os
# 配置参数
pcap_file = 'capture.pcap'
keytab_file = '/path/to/kerberos.keytab'
output_file = 'decrypted_output.json'
# 检查文件是否存在
if not os.path.exists(pcap_file):
print(f"PCAP file '{pcap_file}' does not exist.")
exit(1)
if not os.path.exists(keytab_file):
print(f"Keytab file '{keytab_file}' does not exist.")
exit(1)
# 构建TShark命令
tshark_command = [
'tshark',
'-r', pcap_file,
'-o', f'kerberos.keytab:{keytab_file}',
'-o', 'kerberos.desegment: TRUE',
'-o', 'kerberos.decrypt: TRUE',
'-Y', 'kerberos',
'-T', 'json'
]
# 运行TShark命令
print("Running TShark to decrypt Kerberos packets...")
result = subprocess.run(tshark_command, capture_output=True, text=True)
if result.returncode != 0:
print("Error running TShark:")
print(result.stderr)
exit(1)
# 将输出保存为JSON文件
with open(output_file, 'w') as f:
f.write(result.stdout)
print(f"Decrypted data saved to {output_file}")
# 读取并解析JSON数据
with open(output_file, 'r') as f:
try:
data = json.load(f)
except json.JSONDecodeError as e:
print(f"Error parsing JSON data: {e}")
exit(1)
# 提取需要的信息
records = []
for packet in data:
layers = packet['_source']['layers']
kerberos = layers.get('kerberos', {})
if kerberos:
# 提取Kerberos主体信息
principal_name = kerberos.get('kerberos.sname', [''])[0]
client_name = kerberos.get('kerberos.cname', [''])[0]
# 提取时间戳
timestamp = layers['frame']['frame.time']
records.append({
'timestamp': timestamp,
'principal_name': principal_name,
'client_name': client_name
})
# 转换为DataFrame
df = pd.DataFrame(records)
print(df)
# 数据分析和可视化
client_counts = df['client_name'].value_counts()
print("Client Name Counts:")
print(client_counts)
# 绘制柱状图
client_counts.plot(kind='bar')
plt.xlabel('Client Name')
plt.ylabel('Count')
plt.title('Kerberos Client Name Distribution')
plt.tight_layout()
plt.show()1. 服务器集群
数量:至少3台服务器,分别用于以下角色:
- Hive服务器节点:运行Hive服务,处理数据存储和查询。
- Kerberos服务器(KDC):提供Kerberos认证服务。
- 客户端/开发节点:用于开发、测试和运行解密算法。
配置建议:
- CPU:每台服务器至少4核Intel Xeon或AMD等效处理器。
- 内存:每台服务器至少16GB RAM,推荐32GB以上,以满足大数据处理需求。
- 存储:
- 系统盘:至少200GB SSD,用于操作系统和软件安装。
- 数据盘:根据需要配置HDD或SSD,用于存储Hive数据和日志,容量至少1TB。
- 网络:千兆以太网接口,支持高速数据传输,最好配备万兆网卡以提高网络性能。
- 操作系统:CentOS 7或以上版本,或其他兼容的Linux发行版。
Hive大数据平台:
- 版本:建议使用最新稳定版本,确保兼容性和功能完整性。
- 组件:Hadoop、Hive、HDFS、YARN等。
Kerberos认证服务:
- 版本:MIT Kerberos或Heimdal Kerberos最新稳定版本。
- 配置:根据实际需求配置Realm、KDC、Principal等。
利用Python自动化解密Hive与Kerberos通信加密流量的实现与优化
目标:结合Hive大数据平台的知识,利用Python脚本自动化地将Keytab文件导入Wireshark(TShark),实现对Kerberos协议加密部分的直接解包和分析,提高解密的准确性和效率。
一、背景与需求分析
1. Hive与Kerberos的关系
- Hive:基于Hadoop的大数据仓库工具,允许对大型数据集进行查询和分析。
- Kerberos:网络认证协议,用于在不安全的网络中提供安全的身份验证。
在企业级大数据环境中,Hive通常部署在安全模式下,使用Kerberos进行身份认证,以保护数据的安全性。然而,这也使得Hive与客户端之间的通信被Kerberos加密,给网络分析和故障排除带来了挑战。
2. 解密需求
- 故障诊断:需要查看Hive与Kerberos之间的通信细节,分析问题根源。
- 性能优化:通过分析解密后的流量,找出性能瓶颈。
- 安全审计:检测潜在的安全威胁和不合规行为。
3. 现有技术的局限
- 手动操作繁琐:使用Wireshark解密需要手动配置,效率低下。
- 自动化程度低:无法满足大规模或持续监控的需求。
- 准确性不足:在复杂的环境中,可能出现解密失败或不完整的情况。
二、实现思路
- 自动获取并更新Keytab文件:确保Keytab文件与Hive服务的密钥同步。
- 使用Python脚本调用TShark:自动化地将Keytab文件导入,解密Kerberos流量。
- 解析解密后的数据:利用Python对解密后的数据进行解析和分析。
- 优化解密算法:提高解密的准确性和效率,适应Hive的复杂环境。
三、详细实现过程
1. 环境准备
- 软件安装:
Wireshark和TShark:用于网络流量捕获和解密。
Python 3:用于编写自动化脚本。
必要的Python库:
bash
Copy code
pip install pandas pyshark paramiko
2. 自动获取Keytab文件
由于Hive服务的密钥可能会定期更新,需要确保Keytab文件也是最新的。可以使用Python脚本通过SSH从Hive服务器上获取最新的Keytab文件。
示例代码(获取Keytab文件):
python
Copy code
import paramiko def fetch_keytab(remote_host, username, password, remote_path, local_path): ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect(remote_host, username=username, password=password) sftp = ssh.open_sftp() sftp.get(remote_path, local_path) sftp.close() ssh.close() # 示例使用 remote_host = 'hive-server.example.com' username = 'user' password = 'pass' remote_keytab_path = '/etc/security/keytabs/hive.service.keytab' local_keytab_path = '/path/to/local/hive.service.keytab' fetch_keytab(remote_host, username, password, remote_keytab_path, local_keytab_path)
注意:确保脚本有权限访问Hive服务器,并且在安全和合规的前提下操作。
3. 捕获Hive与Kerberos的网络流量
可以使用dumpcap或tcpdump等工具捕获Hive与Kerberos之间的通信流量,保存为pcap文件。
示例命令:
bash
Copy code
tcpdump -i any -w hive_kerberos.pcap port 88 or port 10000
- 端口说明:
- 88:Kerberos默认端口。
- 10000:HiveServer2默认端口(可能需要根据实际情况调整)。
4. 使用Python脚本调用TShark解密流量
利用Python脚本,调用TShark解密捕获的流量。
示例代码(解密流量):
python
Copy code
import subprocess import json import pandas as pd import os def decrypt_kerberos_traffic(pcap_file, keytab_file, output_file): # 检查文件是否存在 if not os.path.exists(pcap_file): print(f"PCAP file '{pcap_file}' does not exist.") return if not os.path.exists(keytab_file): print(f"Keytab file '{keytab_file}' does not exist.") return # 构建TShark命令 tshark_command = [ 'tshark', '-r', pcap_file, '-o', f'kerberos.keytab:{keytab_file}', '-o', 'kerberos.desegment: TRUE', '-o', 'kerberos.decrypt: TRUE', '-Y', 'kerberos || hadoop.rpc', '-T', 'json' ] # 运行TShark命令 print("Running TShark to decrypt Kerberos packets...") result = subprocess.run(tshark_command, capture_output=True, text=True) if result.returncode != 0: print("Error running TShark:") print(result.stderr) return # 将输出保存为JSON文件 with open(output_file, 'w') as f: f.write(result.stdout) print(f"Decrypted data saved to {output_file}") # 示例使用 pcap_file = 'hive_kerberos.pcap' keytab_file = '/path/to/local/hive.service.keytab' output_file = 'decrypted_hive_kerberos.json' decrypt_kerberos_traffic(pcap_file, keytab_file, output_file)
说明:
- 过滤器调整:
'-Y', 'kerberos || hadoop.rpc'用于过滤Kerberos和Hadoop RPC相关的数据包。 - 加密类型匹配:确保Keytab文件包含与Hive服务使用的加密类型一致的密钥。
5. 解析解密后的数据
使用Python读取解密后的JSON数据,提取Hive与Kerberos通信的关键信息。
示例代码(解析数据):
python
Copy code
def parse_decrypted_data(json_file): with open(json_file, 'r') as f: try: data = json.load(f) except json.JSONDecodeError as e: print(f"Error parsing JSON data: {e}") return records = [] for packet in data: layers = packet['_source']['layers'] kerberos = layers.get('kerberos', {}) hadoop_rpc = layers.get('hadoop_rpc', {}) if kerberos: # 提取Kerberos相关信息 client_name = kerberos.get('kerberos.cname', [''])[0] principal_name = kerberos.get('kerberos.sname', [''])[0] timestamp = layers['frame']['frame.time'] records.append({ 'timestamp': timestamp, 'protocol': 'Kerberos', 'client_name': client_name, 'principal_name': principal_name }) elif hadoop_rpc: # 提取Hadoop RPC相关信息 method_name = hadoop_rpc.get('hadoop_rpc.method_name', [''])[0] timestamp = layers['frame']['frame.time'] records.append({ 'timestamp': timestamp, 'protocol': 'Hadoop RPC', 'method_name': method_name }) df = pd.DataFrame(records) print(df) return df # 示例使用 df = parse_decrypted_data(output_file)
6. 优化解密算法
为了提高解密的准确性和效率,可以考虑以下优化:
- 并行处理:对于大型
pcap文件,使用多进程或多线程加速解密过程。 - 增量解密:对持续产生的流量,采用增量方式解密新捕获的数据包。
- 错误处理:增加对异常情况的处理,确保脚本的稳定性。
示例(并行处理):
python
Copy code
from multiprocessing import Pool def process_packet(packet): # 解析单个数据包的逻辑 # ... return parsed_data def parse_decrypted_data_parallel(json_file): with open(json_file, 'r') as f: try: data = json.load(f) except json.JSONDecodeError as e: print(f"Error parsing JSON data: {e}") return with Pool(processes=4) as pool: results = pool.map(process_packet, data) df = pd.DataFrame(results) print(df) return df # 示例使用 df = parse_decrypted_data_parallel(output_file)
四、结合Hive知识进行深入分析
通过解密后的数据,可以对Hive的操作进行深入的分析:
- 查询性能:分析Hive查询的执行情况,找出耗时长的步骤。
- 安全审计:检查用户的访问行为,确保符合权限管理策略。
- 资源优化:根据通信数据,调整Hive集群的配置,提升整体性能。
示例(分析Hive查询):
python
Copy code
def analyze_hive_queries(df): # 过滤Hadoop RPC的Method Name为ExecuteStatement的记录 query_records = df[df['method_name'] == 'ExecuteStatement'] # 统计每个用户的查询次数 query_counts = query_records['client_name'].value_counts() print("Query Counts by User:") print(query_counts) # 可视化 query_counts.plot(kind='bar') plt.xlabel('User') plt.ylabel('Query Count') plt.title('Hive Query Counts by User') plt.tight_layout() plt.show() # 示例使用 analyze_hive_queries(df)
五、注意事项
合法性与合规性:
- 授权操作:确保在授权的情况下进行网络数据的捕获和解密。
- 数据隐私:遵守数据保护法规,防止敏感信息泄露。
安全性:
- Keytab文件保护:妥善保管Keytab文件,限制访问权限。
- 加密算法支持:确保TShark和Wireshark支持Hive使用的Kerberos加密算法。
性能优化:
- 资源管理:解密大型
pcap文件可能需要大量的计算资源,注意系统的负载。 - 脚本优化:针对性能瓶颈进行优化,如采用更高效的数据结构和算法。
- 资源管理:解密大型
六、总结与展望
通过结合Hive大数据平台的知识,利用Python脚本自动化地将Keytab文件导入Wireshark(TShark),实现了对Kerberos协议加密部分的直接解包和分析。
主要优势:
- 自动化程度高:减少手动配置,提高效率。
- 准确性提升:通过优化解密算法,提高了解密的成功率和准确性。
- 可扩展性强:脚本可以根据需要进行定制,适应不同的分析需求。
未来工作:
- 实时监控:扩展脚本,实现对Hive与Kerberos通信的实时解密和分析。
- 深度集成:将解密和分析功能集成到大数据运维平台,实现统一的监控和管理。
- 机器学习应用:利用解密后的数据,结合机器学习算法,进行异常检测和预测分析。
Daily Problem
更新: 5/3/2025 字数: 0 字 时长: 0 分钟