Daily Study
更新: 12/29/2025 字数: 0 字 时长: 0 分钟
Daily Plan
#todo
Go map无序的原因
map深入理解链接:map 的实现原理 | Go 程序员面试笔试宝典
遍历Map初始化导致
遍历map的操作for range 流程如下图所示: 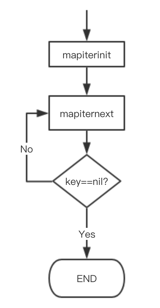 在 mapiterinit 函数中包含会对hiter 迭代器进行初始化,其中包括这样的操作导致遍历无序:
在 mapiterinit 函数中包含会对hiter 迭代器进行初始化,其中包括这样的操作导致遍历无序:
// 1. 生成基础的随机数 (32位)
r := uintptr(fastrand())
// 2. 针对超大 map 的特殊处理
// 这个 if 判断的是:当前 map 的尺寸指数 B 是否已经大到快要超出单个32位随机数所能覆盖的范围了, bucketCntBits是一个常量3,减去 bucketCntBits 是为了处理一些边界和内存分配的细节 ?
if h.B > 31-bucketCntBits {
// 3. 生成另外32位随机数并拼接到高位,形成一个64位随机数
r += uintptr(fastrand()) << 31
}
// 从哪个 bucket 开始遍历
it.startBucket = r & (uintptr(1)<<h.B - 1)
// 从 bucket 的哪个 cell 开始遍历
it.offset = uint8(r >> h.B & (bucketCnt - 1))Map的无序写入与扩容导致
首先,Map的写入要经过Hash确定具体的Bucket以及其中的cell,并且在写入的过程中会发生Hash碰撞,这里采用的是链表法存到Bucket中不同的cell,以及超过单个Bucket中cell大小后,通过overflow指针连接一个新的Bucket存储 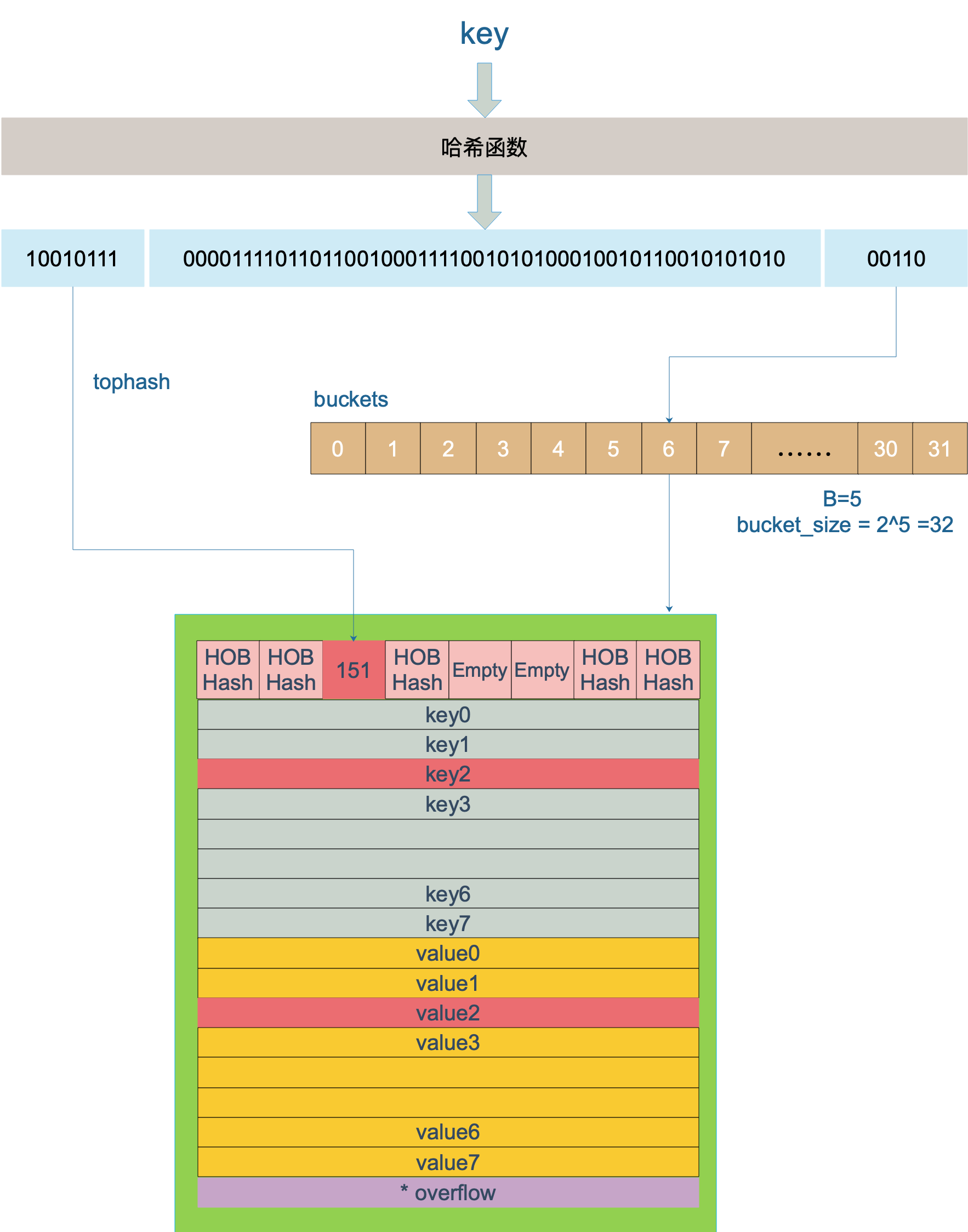
然后由于Map的扩容过程,分为成倍扩容和等量扩容两种,对应如下两种条件:
- 装载因子
loadFactor := count / (2^B)超过阈值,源码里定义的阈值是 6.5。元素太多,而bucket数量太少,将B加1成倍扩容。 overflow的 bucket 数量过多:当 B 小于 15,也就是 bucket 总数 2^B 小于 2^15 时,如果 overflow 的 bucket 数量超过 2^B;当 B >= 15,也就是 bucket 总数 2^B 大于等于 2^15,如果 overflow 的 bucket 数量超过 2^15。此时元素没那么多,但是 overflow bucket 数特别多,说明很多 bucket 都没装满。解决办法就是开辟一个新 bucket 空间,将老 bucket 中的元素移动到新 bucket,使得同一个 bucket 中的 key 排列地更紧密。这样,原来,在 overflow bucket 中的 key 可以移动到 bucket 中来。结果是节省空间,提高 bucket 利用率,map 的查找和插入效率自然就会提升。
// src/runtime/hashmap.go/mapassign
// 触发扩容时机
if !h.growing() && (overLoadFactor(int64(h.count), h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
}
// 装载因子超过 6.5
func overLoadFactor(count int64, B uint8) bool {
return count >= bucketCnt && float32(count) >= loadFactor*float32((uint64(1)<<B))
}
// overflow buckets 太多
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B < 16 {
return noverflow >= uint16(1)<<B
}
return noverflow >= 1<<15
}而扩容的过程中,会发生Key/Value的搬迁过程,主要由growWork()函数执行,此时位置又会发生变动,具体的扩容过程见前面的链接。
func growWork(t *maptype, h *hmap, bucket uintptr) {
// 确认搬迁老的 bucket 对应正在使用的 bucket
evacuate(t, h, bucket&h.oldbucketmask())
// 再搬迁一个 bucket,以加快搬迁进程
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}为什么要设置成无序
- 保证语言规范的稳定性和代码健壮性。如果采用顺序遍历,map底层发生变化(例如,为了优化性能,从一种哈希算法换成另一种,或改变了扩容策略),会引发一些列依赖问题。因此直接从源头上,加上一个随机种子来强化这种无序。
- 防范哈希冲突攻击,例如
Hash-flooding D DoS attack(哈希洪水攻击)攻击者破解了Hash函数,然后恶意的构造大量相同的键(例如发一个http post携带大量同类键),这些键会被hash到同一个桶,这时hash表就退化成一个链表,耗费大量CPU资源,导致服务崩溃。
Redis的时间开销
原来是要分类讨论~
参考:Redis中常见的延迟问题_redis分布式锁 1秒超过1千不能获取-CSDN博客
Redis 在不同的软硬件环境下,它的性能表现差别特别大,不同CPU、不同SSD,都会极大影响Redis的性能表现。服务器配置比较低时延迟为 10ms 时,才认为 Redis响应变慢了,但是如果配置比较高,那么可能延迟是 1ms 时就可以认为 Redis 变慢了。在整个应用系统中,Redis 只是其中的一个环节,需要综合分析 Redis 是否瓶颈
一般情况下,计算机访问一次SSD磁盘的时间大概是50~150微秒;如果是传统的硬盘,需要的时间更长,大概是1~10毫秒;而访问一次内存的时间大概是120纳秒。因此,可见访问的速度差了快一千倍左右。
Redis基准测试的两种指令
在网络条件好的情况下,使用这两种指令进行测试,取最大延迟作为基线性能
- 方式一:
redis-cli --intrinsic-latency - 方式二:
redis-benchmark
Redis延迟原因
首先通过基准测试找到基准延迟,然后可以利用 CONFIG SET slowlog-log-slower-than 5000 来设置慢日志记录阈值,查看慢日志可以看到详细的日志id/时间/指令/参数,然后进一步分析,有如下几个原因
使用了复杂度高的指令
常使用O(n)以上复杂度的命令,由于Redis是单线程执行命令,因此这种情况Redis处理数据时就会很耗时,例如:
sort:对列表(list)、集合(set)、有序集合(sorted set)中的元素进行排序。在最简单的情况下(没有权重、没有模式、没有 LIMIT),SORT 命令的时间复杂度近似于O(n*log(n))sunion:用于计算两个或多个集合的并集。时间复杂度可以描述为 O(N),其中 N 是所有参与运算集合的元素总数。如果有多个集合,每个集合有不同数量的元素参与运算,那么复杂度会是所有这些集合元素数量的总和。zunionstore:用于计算一个或多个有序集合的并集,并将结果存储到一个新的有序集合中。在最简单的情况下,ZUNIONSTORE 命令的时间复杂度是O(N*log(N)),其中 N 是所有参与计算的集合中元素的总数。keys *:获取所有的 key 操作;复杂度O(n),数据量越大执行速度越慢;可以使用scan命令替代Hgetall:返回哈希表中所有的字段和;smembers:返回集合中的所有成员;
存储大 Key
如果查询慢日志发现,并不是复杂度较高的命令导致的,例如都是SET、DELETE操作出现在慢日志记录中,那么就要怀疑是否存在Redis写入了大key的情况。
大key有多大:
- String 类型的 value 超过 1MB
- 复合类型(List、Hash、Set、Sorted Set 等)的 value 包含的元素超过 5000 个(不过,对于复合类型的 value 来说,不一定包含的元素越多,占用的内存就越多)
产生原因:
- 程序设计不当,比如直接使用 String 类型存储较大的文件对应的二进制数据。
- 对于业务的数据规模考虑不周到,比如使用集合类型的时候没有考虑到数据量的快速增长。
- 未及时清理垃圾数据,比如哈希中冗余了大量的无用键值对。
造成的问题:
- 客户端超时阻塞:由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
- 网络阻塞:每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
- 工作线程阻塞:如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
- 持久化阻塞(磁盘IO):对AOF 日志的影响,使用Always 策略的时候,主线程在执行完命令后,会把数据写入到 AOF 日志文件,然后会调用 fsync() 函数,将内核缓冲区的数据直接写入到硬盘,等到硬盘写操作完成后,该函数才会返回。因此当使用 Always 策略的时候,如果写入是一个大 Key,主线程在执行 fsync() 函数的时候,阻塞的时间会比较久,因为当写入的数据量很大的时候,数据同步到硬盘这个过程是很耗时的。另外两种策略都不影响主线程
如何发现大Key:
--bigkeys指令,但是会阻塞主节点,这种方式只能找出每种数据结构 top 1 bigkey(占用内存最大的 String 数据类型,包含元素最多的复合数据类型)。然而,一个 key 的元素多并不代表占用内存也多,需要我们根据具体的业务情况来进一步判断。SCAN指令:SCAN 命令可以按照一定的模式和数量返回匹配的 key。获取了 key 之后,可以利用 STRLEN、HLEN、LLEN等命令返回其长度或成员数量。- 一些分析RDB快照文件的开源工具
如何处理大Key:
- 利用Hash函数将一个bigkey分割成多个小的key
Unlink指令+lazy-free,采用异步方式删除和释放大Key的内存,避免阻塞主线程
过期删除和内存淘汰延迟
Redis过期策略:定期+惰性两种结合
- Redis的定期删除策略是在Redis主线程中执行的,也就是说如果在执行定期删除的过程中,出现了需要大量删除过期key的情况,那么在业务访问时,必须等这个定期删除任务执行结束,才可以处理业务请求。此时就会出现,业务访问延时增大的问题,最大延迟为25毫秒。
- 为了尽量避免这个问题,在设置过期时间时,可以给过期时间设置一个随机范围,避免同一时刻过期。
Redis内存达到上限,每次写入新数据之前,会根据内存淘汰策略踢出一部分数据,在执行内存淘汰策略时会有一定的延迟(LRU/LFU/Random),并且如果淘汰的有大Key,就会更慢。
持久化延迟和集群延迟
- 如果AOF写回策略采用
Always,会占用主线程,导致延迟 - AOF重写过程如下,第2步将缓冲区中新数据写到新文件的过程中会产生阻塞
fork出一条子线程来将文件重写,在执行BGREWRITEAOF命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子线程创建新 AOF 文件期间,记录服务器执行的所有写命令。- 当子线程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新的 AOF 文件保存的数据库状态与现有的数据库状态一致。
- 最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作。
- fork 耗时:AOF重写和RDB都需要父进程 fork 一个子进程进行数据的持久化,首先会涉及到页表的复制,如果页表过大会导致延迟。
- 在集群中,第一次主从复制是全量复制,延迟较大。Redis扩容采用的同步操作进行数据迁移,也会陷入阻塞