Daily Study
更新: 6/7/2025 字数: 0 字 时长: 0 分钟
Daily Plan
#todo
PentestAssitant运行
BGE-Reranker服务
这里把Reranker服务与主程序分离,达到解耦的效果。
介绍
参考链接:FlagEmbedding/Tutorials/5_Reranking/5.2_BGE_Reranker.ipynb at master · FlagOpen/FlagEmbedding
Reranker是基于BGE的一个重排模型,相当于是关系和裁判或者评审。
核心概念:Reranker Model 不进行大规模的“搜索”。它的唯一任务是,对于一个已经存在的文本对 (query, document),给出一个精确的相关性分数。它判断的是“这个文档在多大程度上是这个问题的真正答案”。
工作方式
- 输入:一个文本对,例如
("Python中GIL的缺点是什么?", "这是一篇介绍GIL原理的文章...")。 - 处理:它使用一种被称为“交叉编码器 (Cross-Encoder)”的架构。它将两个文本拼接在一起(中间用特殊符号分隔),然后同时送入
Transformer模型。这使得模型内部的注意力机制可以充分捕捉query中每个词与document中每个词之间的复杂关系。 - 输出:一个单一的相关性分数(通常是 0 到 1 之间的一个数字),而不是向量。
优缺点
- 优点:
- 精度极高:由于它同时处理查询和文档,能进行非常精细的语义相关性判断,效果远胜于 Embedding Model。
- 缺点:
- 速度极慢:因为它需要对每个
(query, document)对都进行一次完整的神经网络计算。如果要从 100 万个文档中找到最佳答案,就需要运行 100 万次模型,这在计算上是不可行的。
- 速度极慢:因为它需要对每个
实际应用
首先在服务器上新建了一个 Conda 环境,安装 pytorch 和 BGE-Reranker 的相关依赖,然后新建了一个 Reranker_server.py,主要使用 FastAPI 构建了一个 Http 应用,并载入模型运行在指定的端口,然后 PentestAssistant 通过请求相应的端口就可以运行相应的服务。
启动命令:uvicorn reranker_server:app --host 0.0.0.0 --port 8008
这里设计到 Docker 网络通信的问题。细节可参照2025-05-29
- 环境:
PentestAssistant运行在本地的Docker上,Reranker服务运行在服务器,通过端口转发到本地的8008端口。 - 问题:
PentestAssistant如何访问到Reranker服务? - 解决办法:
- 方案一:使用特殊的 DNS 名称
host.docker.internal,将调用reranker服务的 URL 从:http://localhost:8008/rerank,修改为:http://host.docker.internal:8008/rerank。Docker提供了一个特殊的DNS名称host.docker.internal,它会自动解析为宿主机在Docker网络中的内部 IP 地址。 - 方案二:使用宿主机网络模式,此方案会移除容器和宿主机之间的网络隔离,让容器直接共享宿主机的网络栈。
- 方案一:使用特殊的 DNS 名称
BGE相关知识学习
官网链接:FlagEmbedding/README_zh.md at master · FlagOpen/FlagEmbedding
相关内容思维导图: 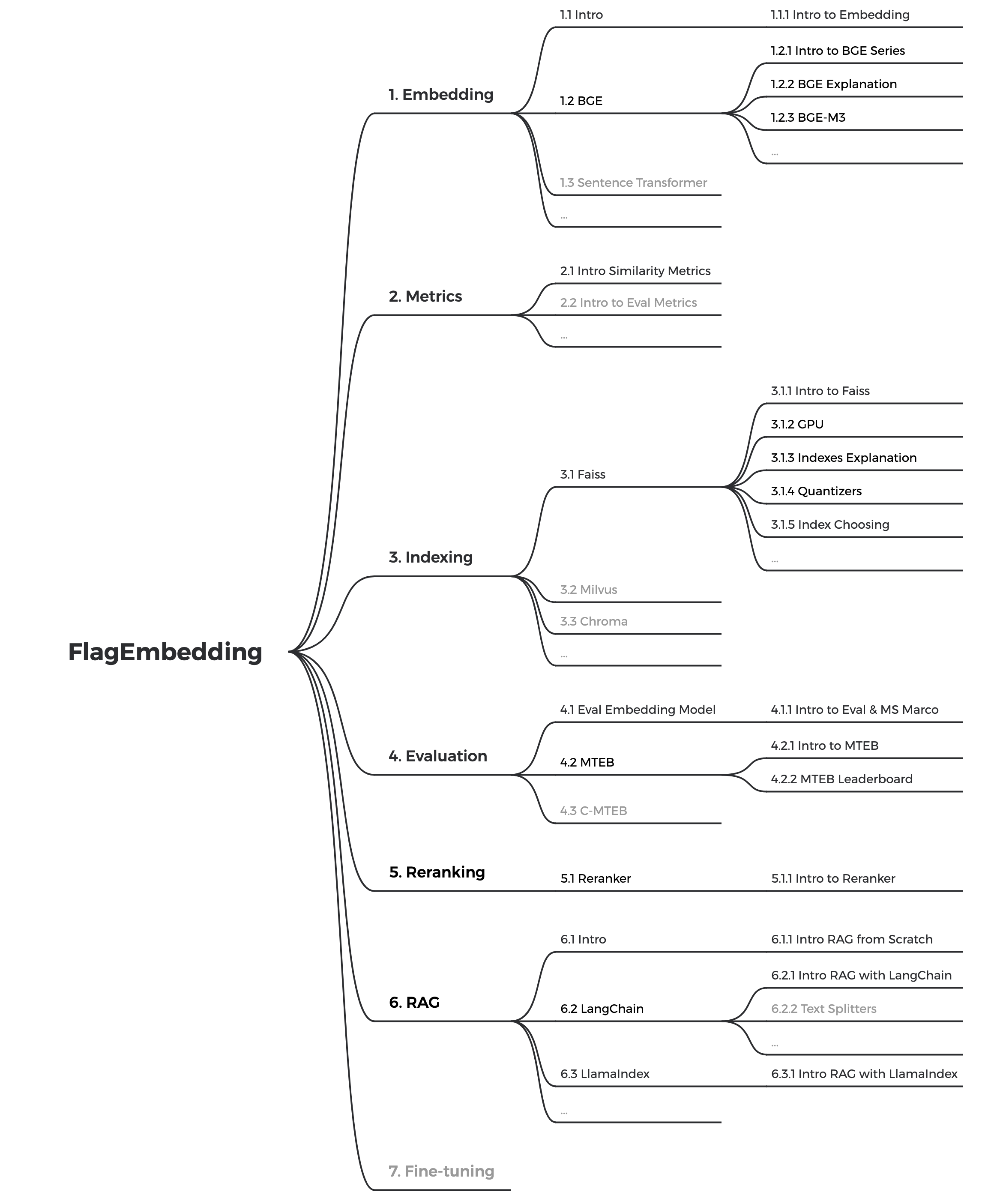
这张思维导图非常系统地勾勒出了围绕 FlagEmbedding 技术栈构建一个完整的语义检索或生成应用(如 RAG)所需要掌握的核心概念。
一张从文本向量化 -> 存储检索 -> 效果评估 -> 结果优化 -> 落地应用 的技术路线图。
1.Embedding (嵌入)
这是所有工作的基础,核心思想是将现实世界的信息(这里特指文本)转换为机器可以理解和计算的数学形式——向量(Vector)。
Intro to Embedding:
- 概念: 文本嵌入(Text Embedding)是一种技术,它将单词、句子或整个文档映射到一个高维的、稠密的浮点数向量。
- 目的: 这个向量能够捕捉文本的语义信息。在向量空间中,意思相近的文本,其对应的向量在空间位置上也更接近。这使得我们可以通过计算向量之间的距离或相似度来判断文本的语义相关性。
BGE (BAAI General Embedding):
- Intro to BGE Series: BGE 是智源人工智能研究院(BAAI)推出的一个高性能通用文本嵌入模型系列,是 FlagEmbedding 项目的明星产品。它在中英文嵌入效果上都处于世界领先水平。
- BGE Explanation: BGE 模型基于深度学习(特别是 Transformer 架构)训练而成,能够高效地将输入文本转换成高质量的语义向量。它有不同尺寸的模型(如 bge-large, bge-base, bge-small)以适应不同场景下的性能和资源需求。
- BGE-M3: 这是 BGE 系列的一个重要升级版。M3 代表多功能 (Multi-Functionality)、多语言 (Multi-Linguality) 和 多粒度 (Multi-Granularity)。它不仅能处理超过100种语言,还能同时执行嵌入(Embedding)和重排(Reranking)任务,并且能灵活处理不同长度(从句子到长文档)的文本输入。
Sentence Transformer:
- 概念: 这是一个基于 PyTorch 和 Transformers 的 Python 框架,专门用于计算句子、文本和图像的嵌入。BGE 等许多现代嵌入模型都是基于或兼容这个框架的。它通过特定的网络结构(如孪生网络 Siamese Network)对预训练语言模型(如 BERT)进行微调,使其可以直接生成能代表整个句子语义的向量,非常适合于语义搜索、聚类等任务。
2.Metrics (度量)
有了向量之后,我们需要一种数学方法来衡量它们之间的关系。
Intro Similarity Metrics:
- 概念: 相似度度量是用来计算两个向量有多“像”的函数。
- 常见方法:
- 余弦相似度 (Cosine Similarity): 最常用的度量方式。它计算两个向量在方向上的夹角余弦值,忽略向量的长度。结果在-1到1之间,值越接近1,代表语义越相似。
- 欧氏距离 (Euclidean Distance): 计算向量空间中两个点的直线距离。距离越小,代表语义越相似。
- 点积 (Dot Product): 计算两个向量的内积。
Intro to Eval Metrics: 这是指评估整个检索系统性能好坏的指标,我们将在第4部分 "Evaluation" 中详细介绍。
3.Indexing (索引)
当你有数百万甚至数十亿个向量时,一个一个地计算查询向量与它们的相似度会非常缓慢。索引就是解决这个问题的技术。
概念: 向量索引是一种数据结构和算法,它能让你在海量的向量数据中,快速地找到与给定查询向量最相似的 K 个邻居(这个过程称为 ANN, Approximate Nearest Neighbor Search,近似最近邻搜索)。
Faiss (Facebook AI Similarity Search):
- Intro to Faiss: 由 Facebook AI 开发的高性能开源库,专门用于高效的向量相似度搜索和海量向量聚类。
- CPU: Faiss 提供了多种在 CPU上运行的索引算法。
- Indexes Explanation: Faiss 内部有多种索引类型,如 IndexFlatL2(暴力搜索,最精确但最慢)、IndexIVFFlat(倒排索引,速度和精度的平衡)和 IndexHNSW(图索引,目前性能最好的索引之一)。
- Quantizers (量化器): 为了节省内存和加快速度,Faiss 使用量化技术(如标量量化 SQ 或乘积量化 PQ)来压缩向量,这会牺牲一点精度来换取巨大的性能提升。
- Index Choosing: 如何根据你的数据量、内存限制、查询速度要求和召回率要求来选择最合适的索引类型和参数。
Milvus: 一个开源的、为大规模向量相似度搜索而设计的向量数据库。它封装了像 Faiss 这样的底层库,并提供了数据管理、可扩展性、多租户等企业级功能,让向量检索变得更简单。
Chroma (or ChromaDB): 一个新兴的、以开发者为中心的开源嵌入数据库。它的设计理念是让AI应用的向量存储和检索变得尽可能简单,非常适合与 LangChain 和 LlamaIndex 等框架集成。
4.Evaluation (评估)
如何科学地衡量你的嵌入模型或整个检索系统的好坏?
Eval Embedding Model:
- Intro to Eval & MS Marco: 评估模型通常需要在一个标准的**基准数据集(Benchmark)**上进行。MS MARCO 是一个由微软发布的大规模真实问答数据集,是评估信息检索系统性能的常用基准之一。
MTEB (Massive Text Embedding Benchmark):
- Intro to MTEB: 一个非常全面的文本嵌入模型评测基准,涵盖了8大类任务(如分类、聚类、检索、重排、STS等)和超过50个数据集。
- MTEB Leaderboard: MTEB 维护一个公开的排行榜,展示了各种主流嵌入模型在其基准上的得分。BGE 模型在这个排行榜上长期名列前茅,是其高质量的有力证明。
C-MTEB: MTEB 的中文版本,专门用于评估模型在中文任务上的表现。BGE 在 C-MTEB 上的优异表现使其成为中文场景下的首选模型之一。
5.Reranking (重排)
重排是提升检索结果质量的关键一步。
Reranker:
- 概念: 这是一个两阶段的检索过程。
- 召回 (Recall): 首先用高效的向量索引(如 Faiss)从海量文档中快速找出可能相关的 Top-K 个候选文档(例如前100个)。这一步追求“快”和“全”。
- 精排 (Rerank): 然后使用一个更强大、更精确但计算量更大的重排模型 (Reranker),对这 Top-K 个候选文档与查询进行更细致的打分和排序,得到最终的排序结果。这一步追求“准”。
- 模型: Cross-Encoder(交叉编码器)类型的模型常被用作 Reranker,因为它能同时看到查询和文档,从而做出更精准的判断。FlagEmbedding 的 BGE-M3 模型也具备 Rerank 功
6.RAG
Intro:
- Intro RAG from Scratch: 从零开始构建 RAG。其核心流程是:当用户提问时,系统首先从外部知识库(如你的公司文档)中检索 (Retrieval) 出最相关的信息片段,然后将这些信息片段和原始问题一起“喂”给大语言模型,让 LLM 基于这些给定的信息来生成 (Generation) 答案。
- 好处: 解决了 LLM 的两大痛点:1) 知识不是最新的;2) 容易产生幻觉(胡说八道)。RAG 允许 LLM 利用私有或实时更新的知识库进行回答。
LangChain:
- Intro RAG with LangChain: LangChain 是一个强大的开源框架,用于简化开发由语言模型驱动的应用程序。它提供了模块化的工具和链(Chains),可以轻松地将 LLM、嵌入模型、向量数据库、Reranker 等组件“粘合”在一起,快速搭建一个 RAG 系统。
- Text Splitters: 在将文档存入向量数据库之前,需要将其切割成合适的块 (Chunks)。Text Splitters 就是 LangChain 中用来做这件事的工具,它有多种切分策略(如按字符数、按 Token 数、递归切分等)。
LlamaIndex:
- Intro RAG with LlamaIndex: 与 LangChain 类似,LlamaIndex 是另一个专注于帮助开发者构建 LLM 应用的框架,尤其侧重于数据和 RAG。它提供了非常丰富的数据连接器、索引结构和查询引擎,让构建和优化复杂的 RAG 流程变得更加方便。
7.Fine-tuning (微调)
当通用模型在你的特定业务场景下效果不够好时,就需要微调。
概念: 在一个已经在海量通用数据上预训练好的模型(如 BGE)的基础上,使用你自己的、带有标注的领域特定数据(Domain-specific Data)对其进行进一步的训练。 目的: 让模型“适应”你所在领域的语言风格、专业术语和数据分布,从而在你的特定任务上(如医疗领域的病历相似度判断)取得更好的表现。