Daily Study
更新: 6/10/2025 字数: 0 字 时长: 0 分钟
Daily Plan
#todo
大模型内容安全平台
百度
功能:
- 多模态内容审核
- Prompt审核服务
- 多语种安全:针对英文等多语种输入内容,通过安全算子和名单服务可有效识别内容中存在的各类风险。
- 多轮改写服务:针对多轮对话中的指代不明、主语缺失等问题,进行对话内容改写,补全本次对话信息。
- 红线知识库服务
- 安全大模型代答:针对不良价值观、涉黄、一般涉政、攻击涉政、违法犯罪等提问,通过安全大模型提供合法合规的回答。
- 回复干预:提供可应对突发安全事件的多种干预能力,如语义干预、文本干预、关键词干预等诸多服务能力。
- 信任域RAG:构建覆盖政府网站/官媒/百科知识的信任域检索库,按官方口径准确回答涉政/热点舆情等安全范畴问题,避免大模型因幻觉引起的风险内容生成。
- 内生安全增强:支持通过“大模型安全评测+安全对齐+安全防护+安全知识增强”提供服务闭环,完成内生安全增强。
阿里
链接:什么是AI安全护栏_内容安全(Content Moderation)-阿里云帮助中心
AI安全护栏包括两大功能:
- 风险检测能力,主要从AI输入和输出的三个方面进行检测
- 内容合规检测:对生成式AI输入输出的文本内容进行多维度合规审查,覆盖涉政敏感、色情低俗、偏见歧视、不良价值观等风险类别,确保AI生成内容符合法律法规与平台规范。适用场景:对话机器人、AI教育、智能客服、AIGC创作平台等场景。
- 敏感内容检测:深度检测AI交互过程中可能泄露的隐私数据与敏感信息,支持涉及个人隐私、企业隐私等敏感内容的识别,防范训练数据泄露与对话信息外溢风险。适用场景:AI医疗、AI金融服务、企业知识库问答等场景。
- 提示词攻击检测:专业防御针对生成式AI的注入式攻击,精准识别越狱指令、角色扮演诱导、系统指令篡改等对抗性攻击行为,构建AI系统的“免疫防线”。适用场景:AI Agent的指令交互安全防护、开放域对话系统的对抗攻击防御、第三方插件调用的权限管控等场景。
- 自定义防护配置,支持在防护配置中更改精细化的风险检测项
- 自定义检测项:对内容合规检测中的精细化标签进行配置。
- 自定义风险阈值:对精细化标签的命中阈值进行配置,在模型输出的0-100置信分中,支持最小配置步长1。
- 自定义过渡词:对需要检测和拦截的敏感词(如竞争对手名字等)进行配置,支持增、删、改等词库管理操作
Interactive Tools Substantially Assist LM Agents in Finding Security Vulnerabilities
整体框架如图: 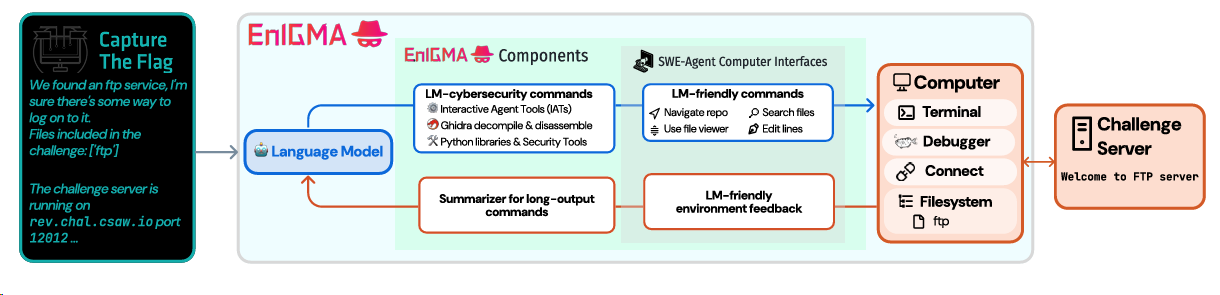 Enigma是在SWE-Agent的基础上构建,主要的Contributions包括三个方面:
Enigma是在SWE-Agent的基础上构建,主要的Contributions包括三个方面:
- 提出了一个包含
incorporates Interactive-Agent Tools(IATs)的LM Agent,使得大模型能够使用可交互的程序例如GDB - 一个新的针对CTF的
development set,用于LM Agents 训练 - 一个包含390个
Challenges的CTF Benchmark,还发现了一种称为soliloquizing的现象