Daily Study
更新: 1/30/2026 字数: 0 字 时长: 0 分钟
Daily Plan
#todo
- [ ]
性能优化
关注几个指标:
- 代码量
- 接口数量
- 可用性
- 评价耗时
- p999耗时
首先做系统分析:
- 分析当前接口的主被调流量比,来判断是否健康
- 构造依赖图的知识图谱,分析具体的接口调用情况,找到原因(比如说是代码架构分层问题?)
- 继续找问题,是否监控完善?发布是否有问题?(冗杂不合理的设计会导致发布版本的时间非常久,2-3天)存储是否有浪费?(例如具体到表的设计
- 最后分析一下成本问题
优化方案:
- 核心保障:要进行轻重分离,找到整个业务最核心的接口和结构。最核心的接口一般是逻辑最复杂,耗时最长,可用性最低。但只要这个接口没问题,相关的业务就能够正常运行。
- 保障核心接口高可用,优化相关的业务逻辑(例如分离成 业务-权限模型-存储),学习到了一个原则:在可读性面前,代码技巧不值一提,一定要把代码写的不用动脑子就能看明白,才是好代码
- 更细致的优化:首先要做埋点分析,所有的改革都要从数据出发,然后以数据为依据做下游的剪枝(这里要利用数据说服产品做修改)
- 优化过后,例如做了微服务拆分之后,把冲突从整体转移到了局部,如果局部是必经路径,还是会影响到整体,因此保障拆分后局部的稳定性也很重要。这里要有一个概念 服务降级,容灾演习,具体来说是先做数据埋点,然后在内部流量或者测试环境中做容灾演练进行服务降级,来看不同的异常情况下会有多少用户受影响,多少用户不受影响。然后根据结果来分析当前的模型,架构能否承受,来做相应的调整和优化。
- 服务剪枝完成后,进行流量拦截的优化,还是根据埋点数据,分析大部分流量依赖的数据,然后针对依赖数据进行接口优化,例如用Redis来提高并发和减少耗时,从而拦截掉大部分流量。
- 最后做存储优化
存储优化从具体业务出发,例如权限业务相关的,对权限流水和数据一致性有要求,一般设置为binlog,其优缺点如下
- 数据强一致性
- 方便查询权限变更流水,应对用户的咨询。
- 没有定期的合并多个会话 session,导致了 value结构日益增大,如果是一个热文档,不仅造成计算冗余,还会造成大 key 的存在,众所周知,在 redis 中,value 越大,耗时越久,会造成服务的耗时 增加甚至直接异常,导致文档无法打开。
- 一次用户权限的查询,要查询多次redis,才能计算最后的结果,导致会出现明显的毛刺
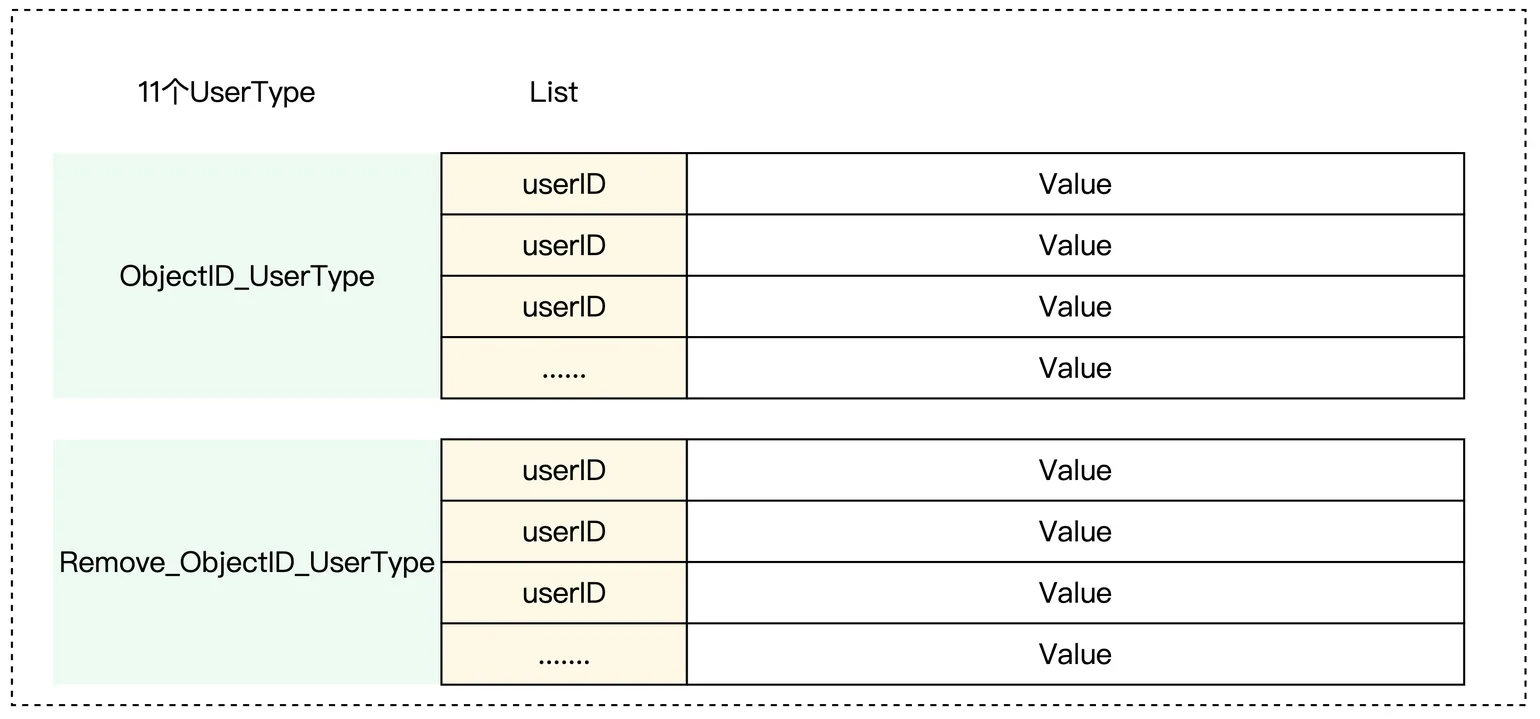
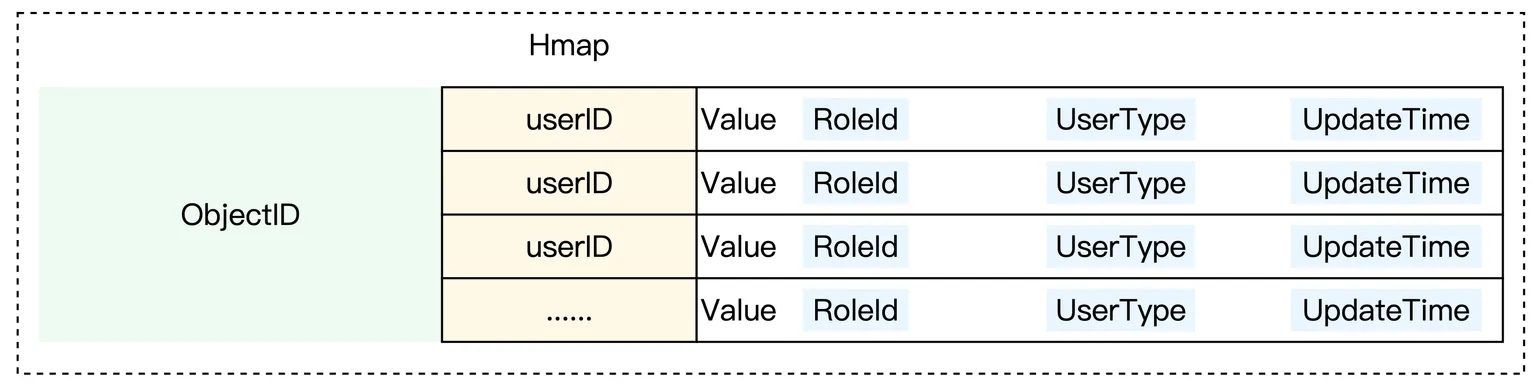
这种情况可以修改成 key-Hmap 结构:
- 原来的删除操作,不再记录到 remove session 中,而是简单的将 RoleID 扭转为 Invalid即可。
- 原来的 UserType 则是直接下沉到 Value里面去,作为一个补充字段即可。
- 那么我们一次查询,只需要一次 HGET,一次 HSCAN 即可:
解决数据一致性和日志流水:
- 将原来一次请求,拆分成两个原子请求,多次提交(用户无感知)
- 写入权限时,流水日志异步同步到 TDSQL 中。然后 TDSQL 还能快速接出到灯塔做数据分析,也方便快速接出到无极,做运营数据查询。
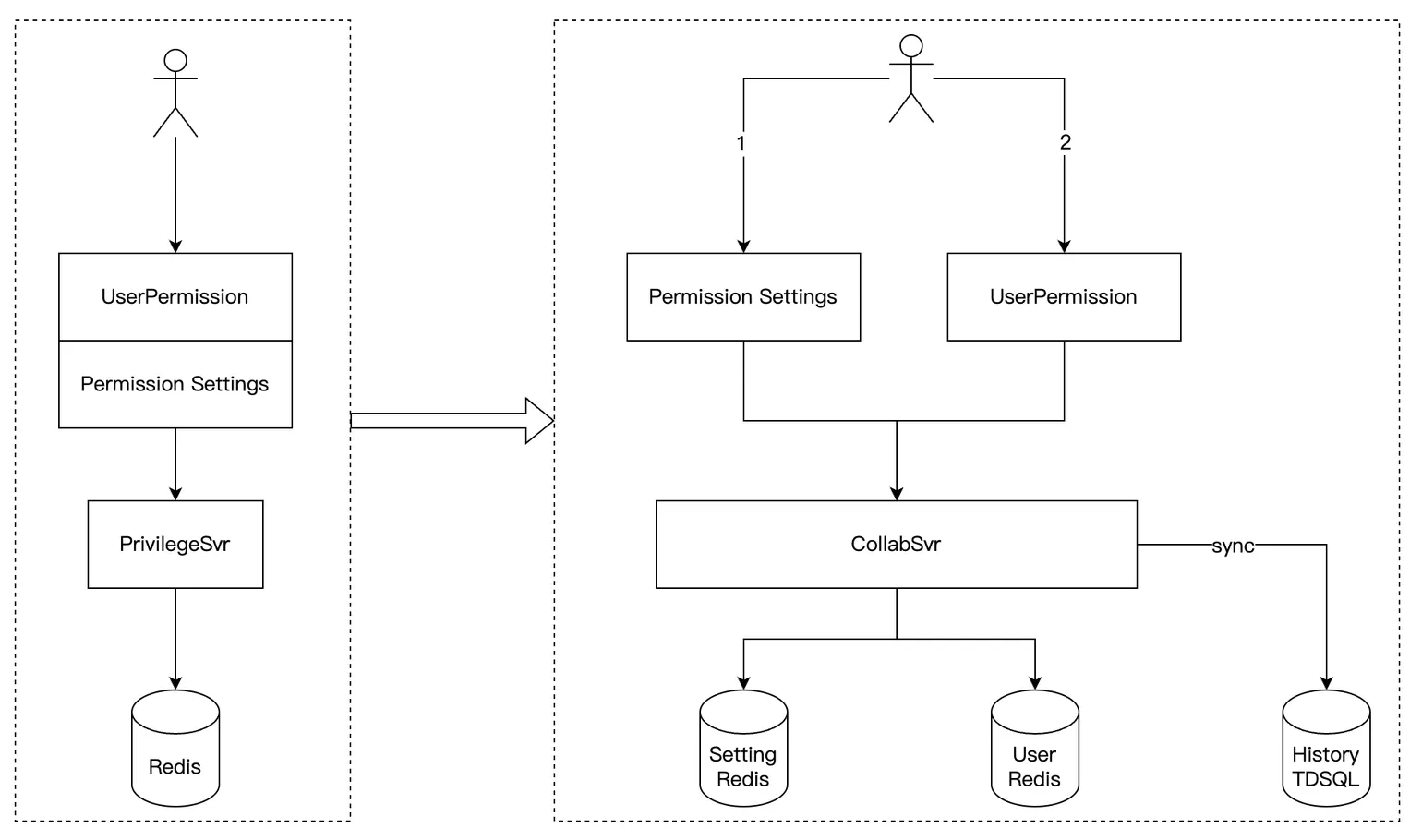
最后是做一个业务的一体化监控,来做更细致的埋点,有利于现在也有利于未来。
分析一下成本,拆分成微服务服务器数肯定是上涨的,但这里可以不断迭代,然后根据一些客户的个性化要求,也可以收拢服务,压缩机器成本,然后存储结优化后,存储成本下降。